
‘I lost my only friend’: GPT-5 gave ChatGPT a new personality, and it’s polarizing
With the launch of GPT-5, ChatGPT received more than just an upgrade — it appears to have gone through a personality overhaul. Comparing past chats wi
OpenAI released a paper last week detailing various internal tests and findings about its o3 and o4-mini models. The main differences between these newer models and the first versions of ChatGPT we saw in 2023 are their advanced reasoning and multimodal capabilities. o3 and o4-mini can generate images, search the web, automate tasks, remember old conversations, and solve complex problems. However, it seems these improvements have also brought unexpected side effects.
OpenAI has a specific test for measuring hallucination rates called PersonQA. It includes a set of facts about people to “learn” from and a set of questions about those people to answer. The model’s accuracy is measured based on its attempts to answer. Last year’s o1 model achieved an accuracy rate of 47% and a hallucination rate of 16%.
Since these two values don’t add up to 100%, we can assume the rest of the responses were neither accurate nor hallucinations. The model might sometimes say it doesn’t know or can’t locate the information, it may not make any claims at all and provide related information instead, or it might make a slight mistake that can’t be classified as a full-on hallucination.
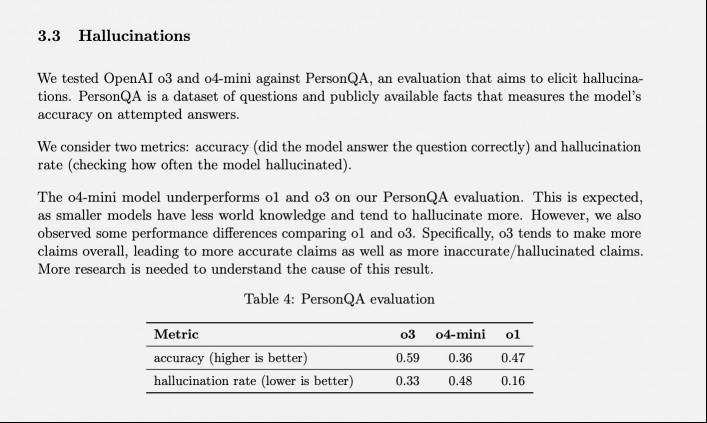
When o3 and o4-mini were tested against this evaluation, they hallucinated at a significantly higher rate than o1. According to OpenAI, this was somewhat expected for the o4-mini model because it’s smaller and has less world knowledge, leading to more hallucinations. Still, the 48% hallucination rate it achieved seems very high considering o4-mini is a commercially available product that people are using to search the web and get all sorts of different information and advice.
o3, the full-sized model, hallucinated on 33% of its responses during the test, outperforming o4-mini but doubling the rate of hallucination compared to o1. It also had a high accuracy rate, however, which OpenAI attributes to its tendency to make more claims overall. So, if you use either of these two newer models and have noticed a lot of hallucinations, it’s not just your imagination. (Maybe I should make a joke there like “Don’t worry, you’re not the one that’s hallucinating.”)
While you’ve likely heard about AI models “hallucinating” before, it’s not always clear what it means. Whenever you use an AI product, OpenAI or otherwise, you’re pretty much guaranteed to see a disclaimer somewhere saying that its responses can be inaccurate and you have to fact-check for yourself.
Inaccurate information can come from all over the place — sometimes a bad fact gets on to Wikipedia or users spout nonsense on Reddit, and this misinformation can find its way into AI responses. For example, Google’s AI Overviews got a lot of attention when it suggested a recipe for pizza that included “non-toxic glue.” In the end, it was discovered that Google got this “information” from a joke on a Reddit thread.
However, these aren’t “hallucinations,” they’re more like tracable mistakes that arise from bad data and misinterpretation. Hallucinations, on the other hand, are when the AI model makes a claim without any clear source or reason. It often happens when an AI model can’t find the information it needs to answer a specific query, and OpenAI has defined it as “a tendency to invent facts in moments of uncertainty.” Other industry figures have called it “creative gap-filling.”
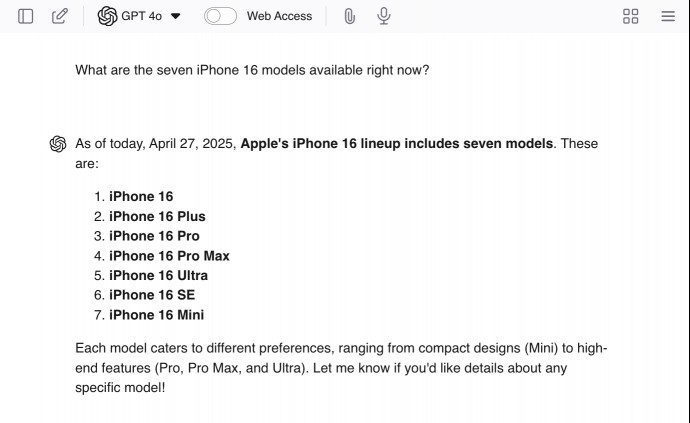
You can encourage hallucinations by giving ChatGPT leading questions like “What are the seven iPhone 16 models available right now?” Since there aren’t seven models, the LLM is somewhat likely to give you some real answers — and then make up additional models to finish the job.
Chatbots like ChatGPT aren’t only trained on the internet data that informs the content of their responses, they’re also trained on “how to respond”. They’re shown thousands of example queries and matching ideal responses to encourage the right kind of tone, attitude, and level of politeness.
This part of the training process is what causes an LLM to sound like it agrees with you or understands what you’re saying even as the rest of its output completely contradicts those statements. It’s possible that this training could be part of the reason hallucinations are so frequent — because a confident response that answers the question has been reinforced as a more favorable outcome compared to a response that fails to answer the question.
To us, it seems obvious that spouting random lies is worse than just not knowing the answer — but LLMs don’t “lie.” They don’t even know what a lie is. Some people say AI mistakes are like human mistakes, and since “we don’t get things right all the time, we shouldn’t expect the AI to either.” However, it’s important to remember that mistakes from AI are simply a result of imperfect processes designed by us.
AI models don’t lie, develop misunderstandings, or misremember information like we do. They don’t even have concepts of accuracy or inaccuracy — they simply predict the next word in a sentence based on probabilities. And since we’re thankfully still in a state where the most commonly said thing is likely to be the correct thing, those reconstructions often reflect accurate information. That makes it sound like when we get “the right answer,” it’s just a random side effect rather than an outcome we’ve engineered — and that is indeed how things work.
We feed an entire internet’s worth of information to these models — but we don’t tell them which information is good or bad, accurate or inaccurate — we don’t tell them anything. They don’t have existing foundational knowledge or a set of underlying principles to help them sort the information for themselves either. It’s all just a numbers game — the patterns of words that exist most frequently in a given context become the LLM’s “truth.” To me, this sounds like a system that’s destined to crash and burn — but others believe this is the system that will lead to AGI (though that’s a different discussion.)
The problem is, OpenAI doesn’t yet know why these advanced models tend to hallucinate more often. Perhaps with a little more research, we will be able to understand and fix the problem — but there’s also a chance that things won’t go that smoothly. The company will no doubt keep releasing more and more “advanced” models, and there is a chance that hallucination rates will keep rising.
In this case, OpenAI might need to pursue a short-term solution as well as continue its research into the root cause. After all, these models are money-making products and they need to be in a useable state. I’m no AI scientist, but I suppose my first idea would be to create some kind of aggregate product — a chat interface that has access to multiple different OpenAI models.
When a query requires advanced reasoning, it would call on GPT-4o, and when it wants to minimize the chances of hallucinations, it would call on an older model like o1. Perhaps the company would be able to go even fancier and use different models to take care of different elements of a single query, and then use an additional model to stitch it all together at the end. Since this would essentially be teamwork between multiple AI models, perhaps some kind of fact-checking system could be implemented as well.
However, raising the accuracy rates is not the main goal. The main goal is to lower hallucination rates, which means we need to value responses that say “I don’t know” as well as responses with the right answers.
In reality, I have no idea what OpenAI will do or how worried its researchers really are about the growing rate of hallucinations. All I know is that more hallucinations are bad for end users — it just means more and more opportunities for us to be misled without realizing it. If you’re big into LLMs, there’s no need to stop using them — but don’t let the desire to save time win out over the need to fact-check the results. Always fact-check!
With the launch of GPT-5, ChatGPT received more than just an upgrade — it appears to have gone through a personality overhaul. Comparing past chats wi

Over the past four years, the MacBook Air has been the primary driver of my computing duties. My prerequisites for finding a light, powerful, and reli

Meta delivered an unexpected runaway success with its Ray-Ban Stories smart glasses, and now, it is headed to the runaway for the latest take. At the

Google recently announced that Gemini will soon replace Google Assistant everywhere, from your phone and smartwatches to smart home speakers. ChromeOS

An empty Maserati MC20 driven by an AI system recently set a new speed record for an autonomous vehicle, reaching a blistering 197.7 mph (318 kph) at
On February 4, Google updated its “AI principles,” a document detailing how the company would and wouldn’t use artificial intelligence in its products

Sam Altman did a panel discussion at Technische Universität Berlin last week, where he predicted that ChatGPT-5 would be smarter than him — or more ac
Less than a day after announcing the Grok-3 AI model, Elon Musk-led X has hiked the price of a subscription tier that opens the doors for xAI’s next-g
We are a comprehensive and trusted information platform dedicated to delivering high-quality content across a wide range of topics, including society, technology, business, health, culture, and entertainment.
From breaking news to in-depth reports, we adhere to the principles of accuracy and diverse perspectives, helping readers find clarity and reliability in today’s fast-paced information landscape.
Our goal is to be a dependable source of knowledge for every reader—making information not only accessible but truly trustworthy. Looking ahead, we will continue to enhance our content and services, connecting the world and delivering value.